
最近趣味でPython のSeleniumを使ってスクレイピングしているんだが
なぜか要素が取得できないことがある。
技術的な原因としては
以下2点のことがあるみたい。
- 取得したい要素にiframeが使われている
- 取得したい要素がshadow-rootで囲まれている
この内、「1.iframeが含まれている場合のスクレイピング」については
ネットでググれば大抵のこと書いてあるから割愛したい。
ここでは「2. shadow-rootが使われた場合のスクレイピング」についてまとめる。
ちなみに私自身、ITエンジニアでもないタダのド素人だから
素人目にみてわかるように書きたいと思う。
※玄人の人は許してね
ちなみにshadow-root攻略に3日かかった
そのくらい希少価値があるものだと思いたい。
1. shadow-rootについて
Chrome開いてF12ボタンを押すと、サイトのHTMLを確認できるんだが
まれにそのHTMLの中に#shadow-rootという文字が書かれている部分がある。

これが今回要素を取得したい部分。
普通のスクレイピング方法なら
例えばfind_element_by_class_name("test") と入力することによって
class名がtestの要素を抽出可能。
しかし#shadow-rootが使われている場合は違う。
通常の要素抽出方法では
#shadow-rootに囲まれた部分はスクレイピング不可。
と非常にやっかいな代物。
しかし次の方法を使えばスクレイピングが可能になった。
2.shadow-root内のスクレイピング方法
結論をいうと
以下を打ち込めば攻略可能。
- from selenium.webdriver.common.by import By
- item_root = driver.find_element_by_css_selector("div.hogehoge").shadow_root
- item_root.find_element(By.CSS_SELECTOR, "div.foo")
この場合の全体構成はこんなイメージ
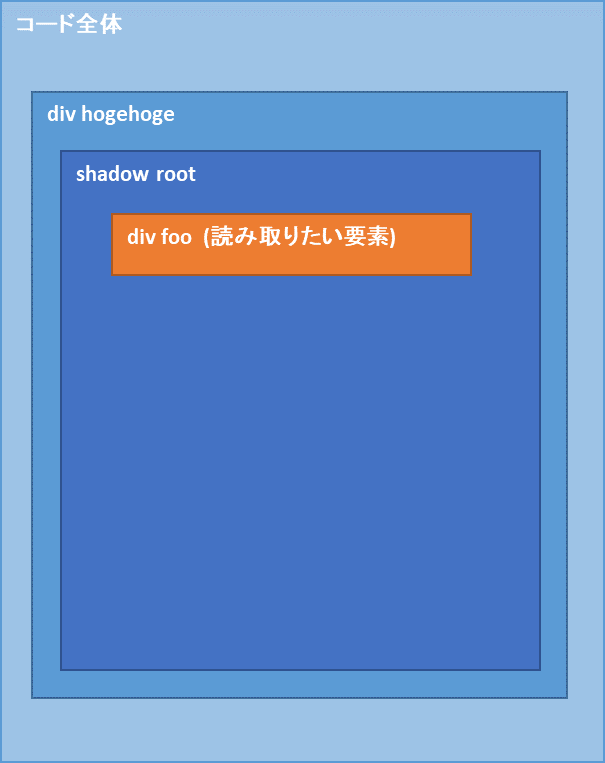
ここの"div.foo"を読み取るために行う作業。
また上記コードを打ち込む前に下準備も必要なので
お忘れなく。
下準備
使用するブラウザchrome v.96以上
確認方法
ブラウザを開いて、右上のハンバーガーマークをクリック
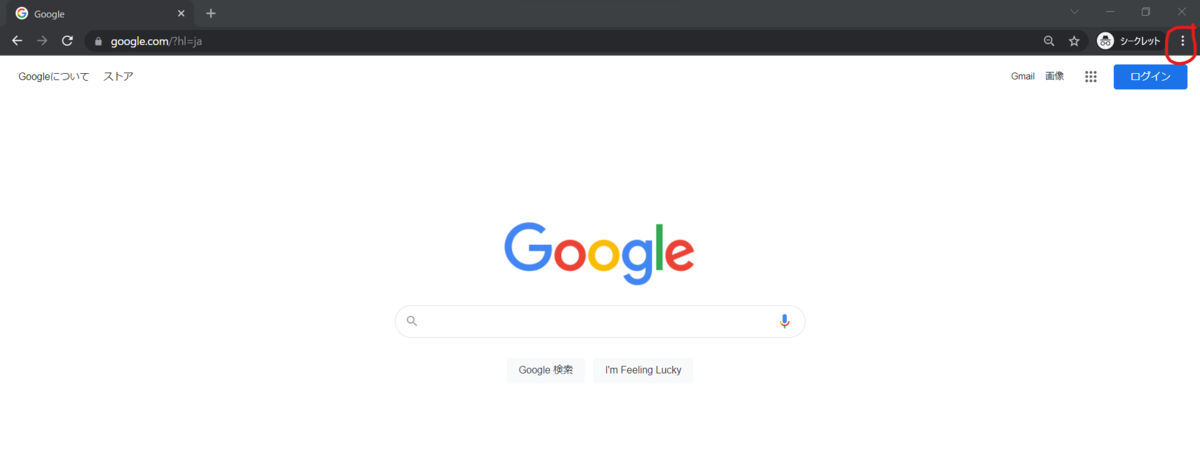
設定の"Chromeについて"をクリック
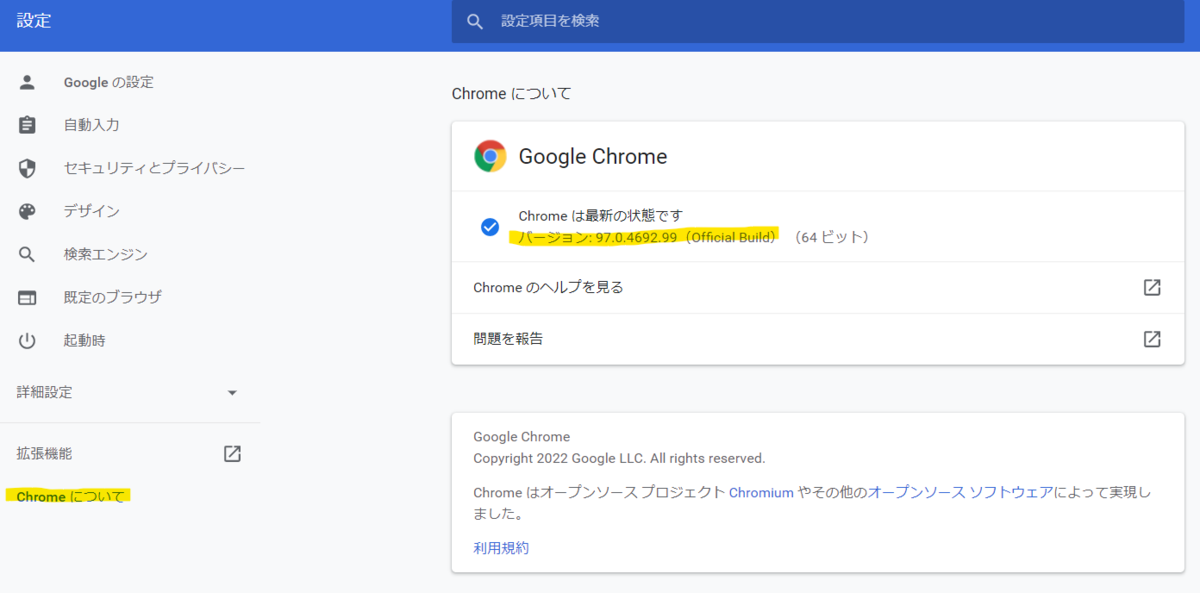
バージョン96以上ならOK
そうでなかったら最新版にアップグレードしよう。
上記"Chromeについて"の設定画面からできるはず
同様にchrome driverもバージョン96以上にアップデートしよう
※chromeブラウザとドライバーのバージョンは揃えること
また使用するSeleniumはVer4.0以上
以下のコマンドを打ち込んでアップグレードしよう
pip install selenium==4.0.0
3. コード解説
コード1行目
- from selenium.webdriver.common.by import By
まずこのコードを頭に入力しよう
詳しくは後述するが、これがないと3行目のコードが認識できない。
絶対に忘れないこと。
コード2行目
- item_root = driver.find_element_by_css_selector("div.hogehoge").shadow_root
こちらでshadow rootが含まれる直前の要素を読み取る。
イメージはこんな感じ

コード3行目
- item_root.find_element(By.CSS_SELECTOR, "div.foo")
最後に
このとき以下を厳守すること
✕ find_element_by_css_selector("div.foo)
○ find_element(By.CSS_SELECTOR,"div.foo")
通常なら✕の表現方法でも抽出可能 (Selenium4.0の場合)
しかしshadow.rootを用いたあとの場合、
✕の表現方法だとエラーを吐きプログラムを回すことが不可能。
今後は✕の表現方法廃止していくみたいだから、
この際覚えよう。
また、○の表現を用いるためには
1行目
- from selenium.webdriver.common.by import By
を入力する必要がある。
今回のコードのイメージはこんな感じ
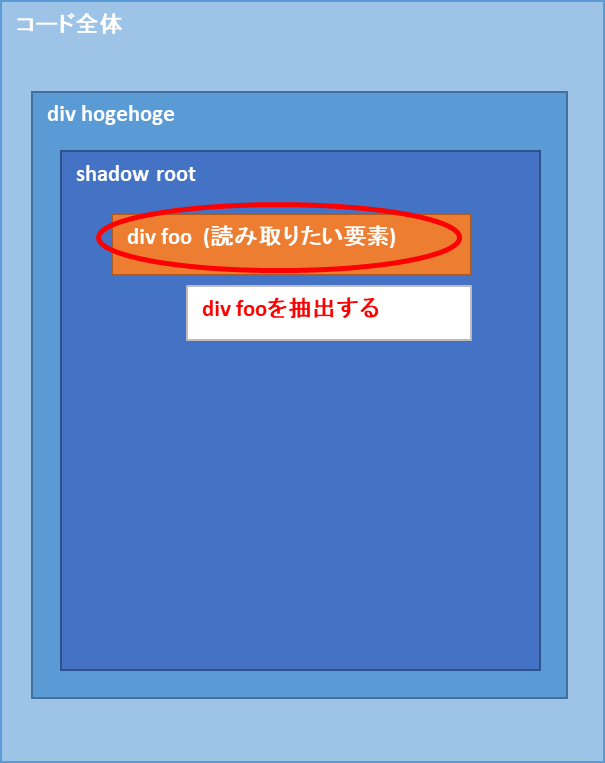
というわけで
ここまでやれば
やっかいなshadow.rootの中身が読み取ることができると思う。
最後になるが私はITエンジニアでも何でもないんで
書き方の決まりの間違えがあるのは許してほしい。
もし指摘されれば訂正する方向でお願いします。
こちらの2サイトを参考にしました。
本当にありがとうございました。
僕のブログ訪問した人は絶対に見てね。
ついでに良かったと思ったらクリックしてほしい。
![]()
![]()